
In the spring of 2019 I undertook a study of potential infrastructure components that could be used to construct a Universal Ledger System. Here’s a report of that effort:
Components chosen included:
- Vagrant Containers
- Scala as the Language
- sbt as the build tool
- Apache Spark as the analytical application
- Play Frameworks as the web server/authoring tooling
The various scripts used in the video are shown at the bottom of this post. The source code can be accessed at GitHub KipTwitchell/universal_ledger.
Conclusion
I had hoped to get much further in building a universal ledger. However, the effort resulted in a much deeper understanding of the infrastructure choices one can make in building these kinds of system, and the challenges in using them. There were a couple of mis-steps, in the web server and database areas, which weren’t always painless to correct.
I think the infrastructure chosen would be adequate to build upon initially, as the system is evolving. Scale, unfortunately, always tests systems very late in the development cycle. But there is a lot that can be done with these elements combined.
Video of Results
This video shows elements of the above running. The different segments of the video can be found as follows:
- Overview 0:00
- Vagrant 1:33
- Initialization Script 9:25
- Derby Script 12:05
- Apache Spark 12:40
- Play Framework 14:00
This is another episode of Coding with Kip, the technical sub-series of Conversations with Kip, the best financial system vlog there is. Literally learn more–about ledgers and financial systems–at LedgerLearning.com.
Watch the series in order at Coding with Kip Playlist
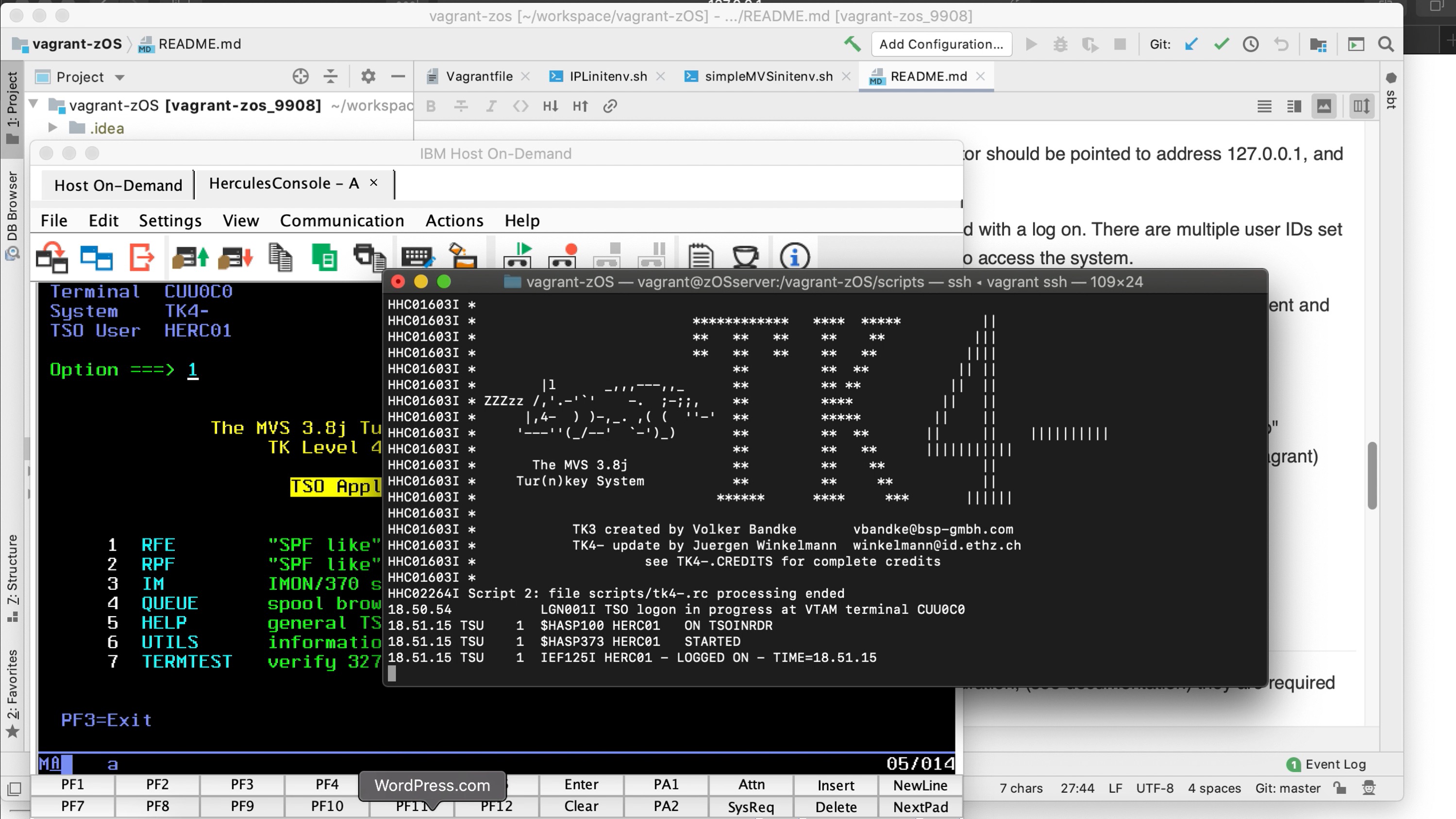
Vagrant Configuration

As a host of others have discovered, a VM is a very effective way of controlling development environment dependencies. There are a number of tools that can be used to create these environments, but I chose Vagrant Boxes for the POC. I was ultimately quite satisfied with choice.
Networking/Multiple VMs
This Vagrant Configuration allows for the potential use of multiple VMs on a single host. I was planning to perhaps try to simulate multiple parties sharing in ledger transactions.
The server (Hostnames) includes: •ulserver •ulclient1 •ulclient2. The default server is ulserver. If no server is specified on a Vagrant command (i.e, “vagrant ssh ulcient1”) then ulserver will be affected.
I was not able to get the networking configuration on my home LAN and my host machine to allow me to do much with the multiple server configurations. The best I could do was to allow for access to a web site hosted inside the VM from the host machine.
Shared Storage
The Vagrant Guest Additions were used to allow access to a shared folder between the host and each VM.
I attempted to shared two folders, one containing the source code for the project and another containing the data files I was attempting to use, which are sizable and thus didn’t want to include them in the project. Sharing multiple files in one VM was feasible in some ways, but not really very effective. In the end I created a script which downloaded the data from a hosting site, which was less efficient than sharing the files locally, but more straightforward to maintain.
Scala and sbt
I continue to be impressed with Scala as a language. It has a lot of flexibility when it comes to Java integration, including running on Java VMs on multiple hosts, but also multiple programming styles, and pretty good performance.
Because of this choice, I used sbt as the build tool for the project.

I was able to construct the project with multiple sub projects. Each inherits the attributes in the project ‘build.sbt” member, highlighted in the graphic. This project had no dependencies wherein a sub program was dependent upon a build at another level.
Web Server

To create a web serve inside the VM, I was limited by ones that would allow me to use Scala. I initially used a Scalatra web-server, but that proved inadequate. It was difficult to get it to respond consistently, appeared to have fewer updates to it (although new releases have recently come out), and didn’t provide the functionality I wanted.
I replaced it with a Play Framework light-weight web server. It is a REST API environment, allowing Scala based templates, which generate complete HTML upon use.
I was able to (1) display prototype screens, (1) construct a web page that uploaded a file from the host to the VM, (3) select a file from the list which then could be submitted as a separate process to Spark, and (4) connect it to the databases (see below) at least in simple ways.
I attempted to find a way to allow it to spawn creation of another process outside of the web server for running Spark, but I wasn’t able to do that. And the final state of the code the uploaded file no longer is listed in the listing screens. I didn’t debug this problem.
It is held as a separate sub project. Once built and running, it can be accessed from the host machine, by pointing to http:\\localhost:9000. It runs within the sbt environment.
Database Components
Parquet Considered
Since I had chosen Spark, I considered Parquet. After using it for a bit, this quote from research about how to take the next step rang very true:
Parquet is a file format rather than a database, in order to achieve an update by id, you will need to read the file, update the value in memory, than re-write the data to a new file (or overwrite the existing file). •
You might be better served using a database if this is a use-case that will occur frequently.
Stack Overflow Answer to Question
I determined that some portion of my needs for the ID assignments processes required an actual database, for which Spark Usage will simply use JDBC connection to the database would be adequate.
Other Databases Considered
I then tried to use a couple of different databases, but ultimately did not progress too far on that study; Aerospike, Derby, and PostgreSQL were all used in various ways, but none of them became an integral part of the solution. For purposes of a Universal Ledger, I determined that structured data capabilities were needed.
This really dropped Derby as a tool. It’s a document database, not well suited to the types of structured data uses needed.
PostgreSQL had the required capabilities, but I wondered about the type of scale I was attempting to build ultimately.
Aerospike may have the abilities, but I was loathed to build in a fixed licensing costs for the start-up phases of the system, and the community edition did not support Spark connectivity.
I was able to install, configure, and get Scala code working against both Aerospike and PostgreSQL Databases in Vagrant. But in the end the project never went so far as to use the database much at all.
Licenses
The IBM license analysis engine determined that none of the licenses used were problematic based upon their criteria.
Initialization Scripts
The following are the initialization scripts in the project.
Vagrant File
The following is the script I ended up using for Vagrant:
# (c) Copyright IBM Corporation. 2018
# SPDX-License-Identifier: Apache-2.0
# By Kip Twitchell
Vagrant.configure("2") do |config|
# These are the vbguest additions for syncing folders
config.vbguest.auto_update = false
config.vbguest.no_remote = true
config.vm.define :ulserver, primary: true do |ulserver|
# ulserver.vm.box = "ktwitchell001/Universal_ledger"
ulserver.vm.box = "geerlingguy/centos7"
# ulserver.vm.network :private_network, ip: "192.168.10.200"
ulserver.vm.network :private_network, type: "dhcp"
ulserver.vm.hostname = "ulserver"
ulserver.vm.synced_folder ".", # <--- this directory for code
"/universal_ledger",
id: "code", type: "virtualbox"
###### enabled for postgreSQL Subproject use
ulserver.vm.network "forwarded_port", guest: 5432, host: 5432, auto_correct: true
###### enabled for Play framework
ulserver.vm.network "forwarded_port", guest: 9000, host: 9000, auto_correct: true
# the following (and in other boxes below) creates a simple hostname file,
# This allows use of hostname in commands in the vm to talk to the other servers
config.vm.provision "shell", inline: <<-SHELL
SHELL
end
config.vm.define :ulclient1, autostart: false do |ulclient1|
ulclient1.vm.box = "geerlingguy/centos7" # <- not tested
# ulclient1.vm.network :private_network, ip: "192.168.10.201"
ulclient1.vm.network :private_network, type: "dhcp"
ulclient1.vm.hostname = "ulclient1"
ulclient1.vm.synced_folder ".", "/universal_ledger", type: "virtualbox"
config.vm.provision "shell", inline: <<-SHELL
SHELL
end
config.vm.define :ulclient2, autostart: false do |ulclient2|
ulclient2.vm.box = "geerlingguy/centos7" # <- not tested
# ulclient2.vm.network :private_network, ip: "192.168.10.202"
ulclient2.vm.network :private_network, type: "dhcp"
ulclient2.vm.hostname = "ulclient2"
ulclient2.vm.synced_folder ".", "/universal_ledger", type: "virtualbox"
config.vm.provision "shell", inline: <<-SHELL
SHELL
end
end
Java, Scala, sbt, and Play Framework components
This script is run after initializing the Vagrant environment. It is dependent upon have a Play Framework project to run accessible in the Vagrant environment.
#!/usr/bin/env bash # * (c) Copyright IBM Corporation. 2019 # * SPDX-License-Identifier: Apache-2.0 # * By Kip Twitchell # This script initializes the Aerospike/CentOS vagrant environment with the following # Elements needed to do Scala development # (1) Update the OS upon initial startup # (2) download wget for use in later commands # (3) download and install Java 8 # (4) download and install Scala 2.11 (to be potentially compatible with Spark if needed) # (5) install sbt # (6) perform an initial compile of the project to initialize sbt further cd /home/vagrant echo '****************************************************' echo '************* update operating system *************' sudo yum -y update echo '*********************************************' echo '************* download and wget *************' sudo yum -y install wget echo '*******************************************************' echo '************* download and install java 8 *************' sudo yum -y install java-1.8.0-openjdk.x86_64 echo "java version:" java -version sudo yum -y install java-1.8.0-openjdk-devel.x86_64 echo "java compiler version:" javac -version sudo cp /etc/profile /etc/profile_backup #Backup the profile file echo 'export JAVA_HOME=/usr/lib/jvm/jre-openjdk' | sudo tee -a /etc/profile echo 'export JRE_HOME=/usr/lib/jvm/jre' | sudo tee -a /etc/profile source /etc/profile echo 'Java home:' echo $JAVA_HOME echo 'JRE home:' echo $JRE_HOME echo '******************************************************' echo '************* download and install scala *************' # cd ~ # in the initial script, not sure it is needed wget http://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.rpm sudo yum -y install scala-2.11.8.rpm echo 'scala version:' scala -version #echo '****************************************************' #echo '************* Initialize PostgreSQL DB *************' #sudo /usr/pgsql-10/bin/postgresql-10-setup initdb echo '************************************************' echo '************* download/install sbt *************' wget https://dl.bintray.com/sbt/rpm/sbt-0.13.16.rpm sudo yum -y install sbt-0.13.16.rpm echo '*****************************************************************************' echo '********************* start-up Play Framework server; **********************' echo '************* test in browser on host at: http://127.0.0.1:9000 *************' echo '*****************************************************************************' (cd /universal_ledger/play; sbt compile run) echo '************************************************************************************' echo '***** Logout of Vagrant ssh and log back in for Path Updates to take effect *******' echo '************************************************************************************'
Spark Installation
Here is the Spark Installation Script
#!/usr/bin/env bash # * (c) Copyright IBM Corporation. 2019 # * SPDX-License-Identifier: Apache-2.0 # * By Kip Twitchell # This script adds Spark to the universal-ledger Scala environment # Run the initenv.sh first to install Java. echo '*****************************************************' echo '************* download and unpack Spark *************' SparkVersion=2.4.1 cd /home/vagrant # TODO test for file already downloaded to improve restartability wget http://archive.apache.org/dist/spark/spark-$SparkVersion/spark-$SparkVersion-bin-hadoop2.7.tgz tar -xvf spark-$SparkVersion-bin-hadoop2.7.tgz # Set Spark Home sudo cp /etc/profile /etc/profile_backup_spark #Backup the profile file echo 'export SPARK_HOME=/home/vagrant/spark-'$SparkVersion'-bin-hadoop2.7' | sudo tee -a /etc/profile export PATH="$SPARK_HOME/bin:$PATH" source /etc/profile echo 'Spark home:' echo $SPARK_HOME echo 'Path' echo $PATH # Error here. Path didn't get up dated with Spark Directory. Not sure what is wrong with the code. # create spark logging direcotry for Spark Session use mkdir /tmp/spark-events #Confirm Spark installation echo "Spark version:" (cd $SPARK_HOME/bin/; bash ./spark-submit --version) echo '*****************************************************************************' echo '********************* Build SAFRonSpark **********************' echo '*****************************************************************************' (cd /universal_ledger/SAFRonSpark/; sbt package) echo '*****************************************************************************' echo '********************* Run initial SAFR on Spark Test; **********************' echo '*****************************************************************************' (bash /universal_ledger/SAFRonSpark/data/InitEnv/RunSAFRonSpark.sh) echo '************************************************************************************' echo '***** Logout of Vagrant ssh and log back in for Path Updates to take effect *******' echo '************************************************************************************' # Here is the command for running the spark code, after it has been compiled. # # /home/vagrant/spark-2.4.0-bin-hadoop2.7/bin/spark-submit --class com.ibm.univledger.runSpark --master local[*] /universal_ledger/spark/target/scala-2.12/spark_2.12-0.1.0-SNAPSHOT.jar # after path update with Spark_home/bin # spark-submit --class com.ibm.univledger.runSpark --master local[*] /universal_ledger/spark/target/scala-2.12/spark_2.12-0.1.0-SNAPSHOT.jar
Derby Installation Script
#!/usr/bin/env bash # * (c) Copyright IBM Corporation. 2019 # * SPDX-License-Identifier: Apache-2.0 # * By Kip Twitchell # This script adds Derby DB to the universal-ledger Scala environment echo '*****************************************************' echo '************* download and unpack derby DB *************' cd /home/vagrant wget http://mirrors.ibiblio.org/apache//db/derby/db-derby-10.14.2.0/db-derby-10.14.2.0-bin.tar.gz tar -xvf db-derby-10.14.2.0-bin.tar.gz # Set Derby Home sudo cp /etc/profile /etc/profile_backup_derby #Backup the profile file echo 'export DERBY_HOME=/home/vagrant/db-derby-10.14.2.0-bin' | sudo tee -a /etc/profile export PATH="$DERBY_HOME/bin:$PATH" source /etc/profile # add a source statement to profile to consistently load the Derby Classpath file echo "source $DERBY_HOME/bin/setEmbeddedCP" | sudo tee -a /etc/profile source /etc/profile echo 'Derby home:' echo $DERBY_HOME echo 'Path' echo $PATH echo "Class Path" echo $CLASSPATH #Confirm Derby installation echo "Derby version:" java org.apache.derby.tools.sysinfo
PostgreSQL Script
This script is not really complete, but a pretty good starting point for a simple installation.
#!/usr/bin/env bash # * (c) Copyright IBM Corporation. 2019 # * SPDX-License-Identifier: Apache-2.0 # * By Kip Twitchell # This script adds PostgrSQL DB to the universal-ledger environment echo '*************************************************************' echo '************* download and unpack postgreSQL DB *************' # The following are commented out as the Vagrant Box chosen already has these installed cd /home/vagrant # Install Extra Packages for Enterprise Linux (EPEL) sudo yum -y install https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm # Install Repository #sudo yum -y install https://download.postgresql.org/pub/repos/yum/10/redhat/rhel-7-x86_64/pgdg-centos10-10-2.noarch.rpm sudo yum -y install https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm # Install Client sudo yum -y install postgresql10 # Install server packages: sudo yum -y install postgresql10-server # Initialize DB and enable auto start sudo /usr/pgsql-10/bin/postgresql-10-setup initdb #sudo systemctl enable postgresql-10 sudo systemctl start postgresql-10 # Set initial environment variables sudo cp /etc/profile /etc/profile_backup_postgres #Backup the profile file echo 'export PGDATA=/var/lib/pgsql/data' | sudo tee -a /etc/profile echo 'export PGHOST=ulserver' | sudo tee -a /etc/profile #echo 'export PGUSER=vagrant' | sudo tee -a /etc/profile #echo 'export PGPASSWORD=univledger' | sudo tee -a /etc/profile export PATH="/usr/pgsql-10/bin:$PATH" source /etc/profile echo 'PG Data:' echo $PGDATA echo 'Path' echo $PATH # Set modify postgreSQL configuration files to allow access from VM host sudo cp /var/lib/pgsql/10/data/postgresql.conf /var/lib/pgsql/10/data/postgresql.conf_backup #Backup the file echo $'listen_addresses = \'*\'' | sudo tee -a /var/lib/pgsql/10/data/postgresql.conf sudo cp /var/lib/pgsql/10/data/pg_hba.conf /var/lib/pgsql/10/data/pg_hba.conf_backup #Backup the file echo 'host all all all trust' | sudo tee -a /var/lib/pgsql/10/data/pg_hba.conf sudo systemctl restart postgresql-10 # #Confirm postgreSQL installation echo "!!!!!!!!!!!!!!!!!!!" echo "postgreSQL version:" /usr/pgsql-10/bin/psql --version echo "!!!!!!!!!!!!!!!!!!!" echo '****************************************************************' echo '************* see additional commands in bottom of *************' echo '************* /universal_ledger/script/postgreSQLinit.sh *************' echo '************* to complete db installation *************' echo '****************************************************************' echo '# execute the following commands at the Vagrant Linux Prompt ' echo '#sudo su - postgres # Logs in as postgres user ID to access databasae ' echo '#psql -f /universal_ledger/scripts/pginit1.sql # runs script establishing initial user ' echo '# ' echo '#exit # logs out of user postgres ' echo '#psql -d univledger -f /universal_ledger/scripts/pginit2.sql # test new users capabilities to make tables and drop them '


{kind=link}
{kind=link}
{kind=link}
{kind=link}
[…] on other POC projects, including the short Raspberry Pi experimentation, and the longer Universal Ledger Infrastructure project, I have recently experimented with a personal mainframe system. These systems are not new […]