Control and Contention
Doug is fond of repeating a conversation he had one day with another consultant that was an expert on a different hardware platform. They were talking about the procedures of replacing failed CPUs within a computer, and Doug was impressed with how well-versed the consultant was in these procedures. Doug asked, “How often do they fail?”
“All the time,” was the response.
I have heard statistics about the amount of down time for some large organizations for specific mainframes, and was impressed that in the course of a whole year it was measured in seconds totaling a few minutes. I wouldn’t be surprised to learn there are mainframes that have run continuously for years. Mainframe crashes are very rare. I have tremendous respect for the operating system.
Those results haven’t come by accident; a lot of thought over a long time has created that ability. And the thought isn’t just by those who design and write the operating system and create the hardware. It also comes from those who make the systems run routinely at specific companies. They tend to be a careful lot, wanting to know something of the way the tools will impact the machine.
That’s why on every project, as we have explained how SAFR works to the project team members, we always anticipated the meeting with systems people. As we outlined the potential performance of SAFR someone always says, “We better meet with so and so.” We would begin by being grilled on what impact it can have and how it can be controlled.
Oops
Those concerns aren’t without merit. There is a very small group of people I know who have mistakenly found ways of impacting various mainframes running SAFR. I am one of them, but am not going to share that story. I will share Mukesh Patel’s story, a long time consultant with SAFR. He once created some custom programs called read exits that would run under SAFR. SAFR executed in parallel mode, each thread calling these programs. Unfortunately, he or someone else created a condition that caused an infinite loop in the exit program, not in SAFR itself.1
Mukesh knew the test he needed to run required reading a large amount of event data to test the new program functions. So he started the job and left for the day. After the jobs had been running for hours, and the infinite loops had kicked in, the monitoring operator, who didn’t know anything about the jobs or Mukesh, decided he would help GVBMR95 finish. So he issued an operating system command to give it a higher priority effectively allowing it to use more CPU time.
When it was explained to me, I was told the operator mistyped the command and gave it the highest priority on the box, higher than the operating system. This meant that no other process or program on the computer would cause the SAFR threads to be swapped off the CPU. In addition to the infinite loop, SAFR also required no IO. The threads would run forever. There were enough threads so that every processor was fully utilized. SAFR, the infinite loop exits, abetted by the operator, took over the machine. The machine had to be IPLed2, the mainframe term for rebooted.
Control Parameters
In our meetings with the systems people, we would begin by explaining that the primary means of controlling GVBMR95 is the JCL parameters. SAFR is subject to all the typical system controls, including job classes, which indicate how long a job can execute and its priority relative to other jobs, space allocation, region size, which indicates how much memory can be used, and others. These parameters have always proven adequate in preventing SAFR from doing things it should not. And for most installations, these parameters are adequate for tuning SAFR runs so that SAFR is used to solve the problems required of it while using the resources that the organization allocates to it.
Additionally, other parameters have been developed over time to allow additional control. These include parameters that indicate how many threads should be executed. The Thread Governor, as it has come to be called, allows whoever defines the SAFR pass (an execution of a set of views reading a set of event files) to say how many disk threads and how many tape threads can be run simultaneously, up to 999 threads each.
The thread governor was developed because of tape drives. The actual number of tape drives available on a machine limited how many event files could be read. Tape is a particularly low cost medium for storage of event files. Because SAFR reads event files serially, reading from and writing to tape is completely acceptable. There is no need for direct or random access which disks provide. But typically the number of tape drives in an environment is substantially lower than the number of disk drives. So, on some projects, a SAFR developer would unwittingly submit a SAFR job that wanted to read 10 tape event files in parallel, when there were only 8 tape drives for example. The job would sit and ask the operator to allocate additional tape drives he would have had to go buy and install to satisfy the request. Finally he would cancel the job saying “Sorry, can’t do that.”
If the logic table contains views which are reading more event files than the thread governor allows, SAFR will begin executing the number of governed threads. When a thread is complete, the next waiting thread is started. Thus the SAFR GVBMR95 processing loop is:
Loop until end of threads Loop until end of event records Loop until end of views Next view Next event record Next thread
GVBMR95 accepts additional parameters to control various debugging and run time parameters.
Having established control of the process, we need to understand the other extreme of what is possible. Simply breaking up event files into a lot of small files to be processed in parallel may not produce any performance gains. It is possible that although GVBMR95 executes parallel threads, that effectively because of system or process configuration, they effectively run serially.
A Parallel Processing Example
Over the years, I have seen Doug explain the details of parallel processing with the following chart.

Figure 132. IBM Mainframe Architecture
When parallel processing starts, depending upon the other programs being run by other users and the control parameters assigned to SAFR, the operating system will assign threads to individual CPUs, shown in the middle of the picture. Let’s suppose that we execute two threads in parallel, and both are assigned at the same time to individual CPUs. Almost immediately the threads will require event file data to be read from disk.
On many computers, the CPU plays some role in transferring data from disk, but not on mainframes. Instead, mainframes have a set of specialized CPUs called channels, represented by CHs around the sides in the diagram. These limited function CPUs only transfer data from disk into memory. Because the threads require data from disk, they are “swapped off” the main CPUs to wait for the data to be made available by the channels. The CPUs move on to other programs.
As discussed in Block Sizes, data is stored on disk in what is called a block. A block is a fixed size for the disk. The event file records might be 100 bytes long, but the block might be 32760 bytes in length. The channels know nothing of the 100 byte record length. They transfer one block, 32760 bytes, for each event file into memory. If two files are on the same non PAV disk (parallel access volume), then the same channel must do the work for both files serially. After a block is in memory, the channels instruct the operating system it has retrieved the data. The operating system then assigns the threads to a CPU. If only one CPU becomes available, only one thread begins processing, by reading the event file data. Thus if the file shares a channel or disk, or there is only one CPU available, we have had no parallelism.
Our potential road blocks to parallelism aren’t through yet. A moment later, perhaps, another CPU becomes available and the other thread is assigned to it. Because each block contains 3,270 records in our 100 byte LR example, for a few milliseconds they might both read data, do lookups, transform fields into sort keys, DT and CT columns, and write records to an area of memory reserved for the output file. If both threads need to write to the same extract file at the same moment, one of the threads will be given permission by the operating system; the other will be told to wait. It may be swapped off the processor if the wait is very long. Again, no parallelism.
Supposing each extract record is also 100 bytes long, at some point one of the threads might attempt to place the 3,277th record into the extract file buffer, the space of memory allocated for the output file. The record won’t fit; it would make the block too large to store on disk. This triggers a call to the operating system to transfer the filled buffer out to disk; to write a block. The thread needing to write the record is swapped off the CPU. The assigned channel takes over and actually writes the block to disk. The other thread might continue processing if it doesn’t require this extract file.
Again, perhaps we have no parallel processing when the last block of the last running thread is transferred into memory, and the thread has read all event records in the input buffer and created all the extract records in the output buffers, the threads can then shut down. GVBMR95 writes a message to the JES Message Log when each thread finishes processing, as shown below:4

Figure 133. JES Message Log Thread Messages
It is possible, therefore, to execute multiple threads, but for those threads to almost never run in parallel. To avoid this, we need to think about contention.
It is difficult to represent parallel processing in a book, but we can see the results of it in the extract program trace. Parallel processing means the extract file record write-order becomes completely random. The records written to the trace output are equally random. Now, looking at the event file DD name in trace becomes important. Note that below, record 5 is being processed in one thread, Event1, and then record two begins being processed in the Event2 thread. Reading the trace requires looking at the thread in addition to the record number and view ID.5
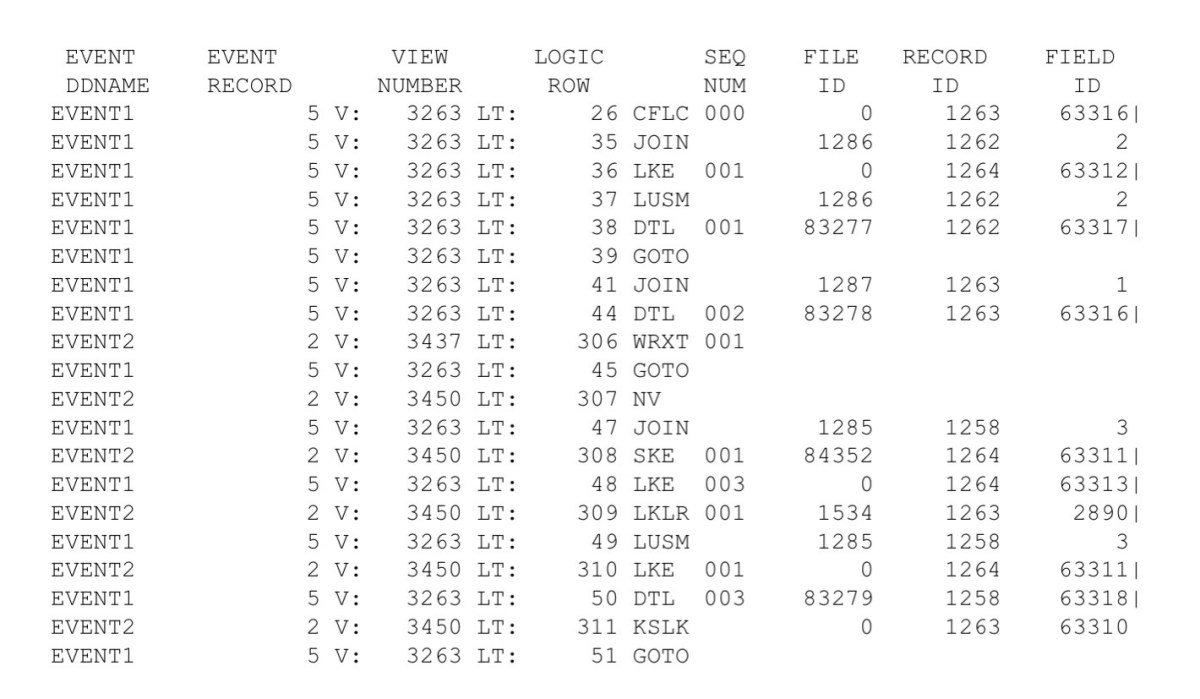
Figure 134. Parallel Processing Trace
Contention
Parallel processing only happens when there is no contention between threads; when the threads do not need to share a resource, such as a portion of memory, or a channel to read the event files sitting on the same physical disk or an extract file.
This is a key point; memory or disk can only be updated by one process or one thread at a time. The operating system provides controls to make sure this happens. In our meeting example, confusion would reign if two people were trying to write to the same spot on the white board at the same time. This fact is what can create contention. Read only access to memory, such as searching the core image reference data, does not require single threading and does not create contention.
Doug has taken pains, and over time the team has discovered places where additional efficiencies can be gained by not sharing resources. For example, Doug made the in memory extract summary buffer unique per view within a thread. Thus the stack of records kept is actually by view by thread (event file). Randall found that significant CPU time can be removed from jobs if extract files are not shared by threads. The threads do not have to test and request access to extract files.6
Here are a few rules of thumb developed over the years. Obviously if a free CPU cannot be used to process a thread, then the machine will not be fully applied to solving the problem. And because threads typically require some IO and are not on a processor all the time, a ratio of three possible threads to each CPU usually allows for sustained parallelism.
There is a constant act of balancing CPU to IO. Some processes end up being CPU bound. In other words, there are not enough CPUs to run the process any faster; the amount of time on each CPU is much longer than the time needed for IO. For example, if a thread read in one record from disk, generated multiple gigabytes of data in memory from that one record, performed many calculations against that data, then summarized it down to write out a single record to the output file, there would be almost no IO involved. More CPUs would be necessary to run the process faster. The extreme of dividing the input records, each to its own file, so that we have one CPU for each input record would not even be enough to make the process run faster.
On the other hand, I have seen processes where the views scan millions of records, but only select a handful; sort of a needle in a haystack problem. Testing each record for inclusion in the output requires very little CPU time. These types of processes are IO bound. Additional files, and channels can be added but at some point the operating system overhead for controlling the number of parallel threads consumes more and more CPU time. So one might achieve a balance between CPU and IO on these kinds of problems, but only because the CPU usage has become inefficient, total elapsed time may decrease, but CPU time may increase to a wasteful extent.
We should note that the threads aren’t the only level of parallelism happening in GVBMR95. GVBMR95 also has overlapped IO. GVBMR95 actually allocates multiple buffers in memory for any one file it is reading or writing. Instead of waiting for the channels to operate against one large portion of memory, either reading it or writing it, GVBMR95 can begin reading data from one buffer while the channels are operating against other buffers. The same is true for writing data; the channels can begin to transfer extract file data to disk while MR95 is writing to other buffers.7
Next we’ll learn about additional techniques to eliminate IO.
Parent Topic: Part 5. The Programmer